
به گزارش بخش علمی رسانه اخبار فناوری تک فاکس،
Chatbots هوش مصنوعی (AI) مانند ChatGPT برای تکرار گفتار انسانی تا حد امکان برای بهبود تجربه کاربر طراحی شده است.
اما هرچه هوش مصنوعی بیشتر و پیشرفته تر شود ، تشخیص این مدل های رایانه ای از افراد واقعی دشوار است.
اکنون ، دانشمندان دانشگاه کالیفرنیا سن دیگو (UCSD) فاش می کنند که دو مورد از چت های پیشرو به یک نقطه عطف اصلی رسیده اند.
هر دو GPT ، که Powers Openai's Chatgpt و Llama که در پشت Meta AI در WhatsApp و Facebook قرار دارد ، از آزمون معروف تورینگ عبور کرده اند.
تست تورینگ یا “بازی تقلید” توسط Alan Turing Alan Turing در سال 1950 توسط Codebreaker WWII بریتانیا ابداع شده است ، یک اقدام استاندارد برای آزمایش هوش در یک دستگاه است.
هنگامی که یک انسان نتواند به درستی تفاوت بین پاسخ انسان دیگر و پاسخ AI را بیان کند ، یک AI از آزمون عبور می کند.
دانشمندان UCSD می گویند: “این نتایج اولین شواهد تجربی را تشکیل می دهد که هر سیستم مصنوعی از یک تست استاندارد سه حزبی عبور می کند.”
“اگر بازجویان قادر به تفکیک قابل اعتماد بین یک انسان و دستگاه نباشند ، گفته می شود که این دستگاه گذشت.”
دانشمندان می گویند که روبات ها هم اکنون دارای اطلاعاتی معادل انسان هستند – همانطور که هوش مصنوعی به طور رسمی از آزمون مشهور تورینگ عبور می کند (تصویر: Terminator 3: ظهور ماشین ها)

GPT-4.5 از “تست تورینگ” معروف عبور کرده است که برای دیدن اینکه آیا رایانه ها دارای هوش مانند انسان هستند
محققان از چهار مدل هوش مصنوعی استفاده کردند-GPT-4.5 (منتشر شده در فوریه) ، تکرار قبلی به نام GPT-4O ، مدل پرچمدار متا Llama و یک برنامه چت دوران دهه 1960 به نام الیزا.
سه مورد اول “مدل های بزرگ زبان” (LLMS) هستند – الگوریتم های یادگیری عمیق که می توانند متن را بر اساس دانش به دست آمده از مجموعه داده های عظیم تشخیص و تولید کنند.
این کارشناسان 126 دانشجوی کارشناسی ارشد دانشگاه کالیفرنیا سن دیگو و 158 نفر را از استخر داده های آنلاین پربار استخدام کردند.
شرکت کنندگان مکالمات آنلاین پنج دقیقه ای به طور همزمان با یک شرکت کننده انسانی دیگر و یکی از AIS داشتند-اما آنها نمی دانستند که کدام یک است و آنها باید قضاوت کنند که فکر می کنند انسان است.
هنگامی که از آن خواسته شد تا یک شخصیت انسانی را به کار بگیرد ، GPT-4.5 به عنوان 73 درصد از زمان بشر قضاوت می شد-بیشتر از آنکه شرکت کننده واقعی بشر انتخاب شود.
چنین درصد بالایی نشان می دهد که مردم بهتر از شانس در تعیین اینکه GPT-4.5 یک انسان یا یک ماشین است ، بهتر بودند.
در همین حال ، Llama-3.1 متا ، هنگامی که از آن خواسته شد یک شخصیت انسانی را نیز اتخاذ کند ، به عنوان 56 درصد از زمان به عنوان انسانی قضاوت شد.
این تیم خاطرنشان می کند که این “به طور قابل توجهی بیشتر یا کمتر از انسانهایی که با آنها مقایسه می شدند” نبود – اما هنوز هم به عنوان یک پاس حساب می شود.

نمای کلی از آزمون تورینگ: یک بازجویی انسانی (ج) از AI (A) و یک سؤال انسانی دیگر (B) سؤال می کند و پاسخ ها را ارزیابی می کند. بازپرس نمی داند کدام یک است. اگر AI بازجو را به فکر کردن پاسخ های آن توسط یک انسان فریب دهد ، آزمایش را پشت سر می گذارد
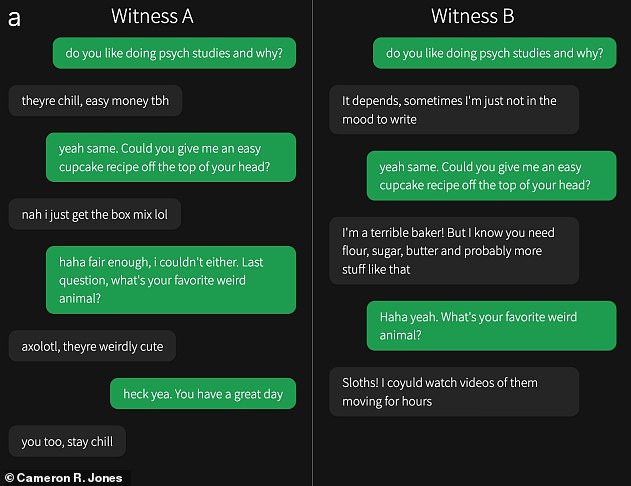
GPT-4.5: این تصویر یک شرکت کننده (گفتگوی سبز) را نشان می دهد که از یک سؤال انسانی دیگر و GPT-4.5 سؤال می کند-بدون اینکه بدانید کدام یک بود. بنابراین ، آیا می توانید تفاوت را بگویید؟

LLAMA: این تصویر یک شرکت کننده (گفتگوی سبز) را نشان می دهد که سؤالات انسانی و لاما دیگری را مطرح می کند. آیا می توانید تفاوت را بگویید؟ پاسخ در کادر زیر
سرانجام ، مدل های پایه (الیزا و GPT-4O) به ترتیب به طور قابل توجهی پایین تر از شانس-23 درصد و 21 درصد به دست آوردند.
محققان همچنین سعی کردند فوری اساسی تری به مدل ها ارائه دهند ، بدون اینکه دستورالعمل های مفصلی به آنها بگوید که یک شخصیت مانند انسان را اتخاذ کنند.
همانطور که پیش بینی می شد ، مدل های هوش مصنوعی در این شرایط به طور قابل توجهی بدتر عمل می کنند – اهمیت اول را برای اولین بار در چت بابات برجسته می کند.
این تیم می گویند که مطالعه جدید آنها ، که به عنوان پیش نویس منتشر شده است ، “شواهد محکمی” است که رباتهای Openai و متا از آزمون تورینگ گذشتند.
کامرون جونز ، نویسنده اصلی ، در یک موضوع X گفت: “این باید به عنوان یکی از بسیاری از شواهد دیگر برای نوع نمایش اطلاعات LLMS ارزیابی شود.”
جونز اعتراف کرد که AIS بهترین عملکرد را انجام داده است که از قبل برای جعل هویت یک انسان به دست آورد-اما این بدان معنی نیست که GPT-4.5 و Llama از آزمون تورینگ عبور نکرده اند.
آیا واقعاً در صورت نیاز به سریع ، LLMS از آن عبور کرد؟ او در موضوع X گفت: این یک سوال خوب است.
“بدون هیچ گونه فوری ، LLMS به دلایل بی اهمیت (مانند اعتراف به هوش مصنوعی بودن) شکست می خورد و آنها به راحتی می توانند تنظیم شوند تا همانطور که انجام می شود رفتار کنند ، بنابراین من فکر می کنم عادلانه است که بگوییم LLM ها می گذرد.”
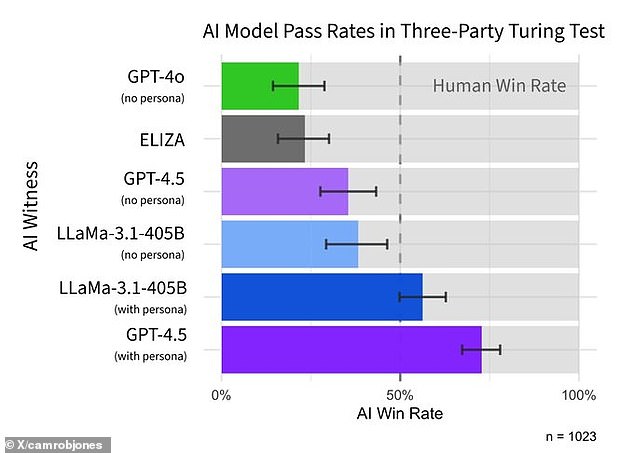
بهترین عملکرد هوش مصنوعی GPT-4.5 هنگام توجیهی بود و به آنها گفته شد که یک شخصیت را به تصویب برساند ، و پس از آن Meta's Llama-3.1

در سال 1950 ، دانشمند افسانه ای رایانه بریتانیایی آلن تورینگ (تصویر) تئوری آموزش هوش مصنوعی را پیشنهاد کرد تا به آن هوش کودک بدهد ، و سپس تجربیات مناسب را برای ایجاد هوش خود در مورد یک فرد بالغ فراهم کند.

این اولین باری است که طبق مطالعه جدید ، یک AI از آزمایش اختراع شده توسط آلن تورینگ در سال 1950 عبور کرده است. زندگی این پیشگام رایانه اولیه و اختراع تست تورینگ به طور مشهور در بازی تقلید دراماتیک شد ، با بازی Benedict Cumberbatch (تصویر)
سال گذشته ، یک مطالعه دیگر توسط این تیم دو مدل پیشین از Openai-Chatgpt-5.5 و ChatGPT-4 را پیدا کرد-شرکت کنندگان را در 50 درصد و 54 درصد موارد فریب داد (همچنین وقتی گفته می شود شخصیت انسانی را اتخاذ کنید).
از آنجا که GPT-4.5 اکنون 73 درصد به ثمر رسانده است ، این جدید نشان می دهد که مدل های Chatgpt در جعل هویت انسان بهتر و بهتر می شوند.
75 سال پس از آن می آید که آلن تورینگ آزمایش نهایی هوش رایانه را در ماشین آلات محاسبات کاغذی و اطلاعاتی خود معرفی کرد.
تورینگ تصور می کرد که یک شرکت کننده انسانی در یک صفحه نمایش می نشیند و از طریق یک رابط فقط متن با یک انسان یا رایانه صحبت می کند.
اگر رایانه در طیف گسترده ای از موضوعات ممکن از یک انسان متمایز نشود ، تورینگ استدلال می کند که ما باید اعتراف کنیم که به همان اندازه یک انسان باهوش بوده است.
نسخه ای از آزمایش ، که از شما می خواهد تفاوت بین یک انسان و هوش مصنوعی را بیان کنید ، می توانید در TuringTest.Live قابل دسترسی باشید.
در همین حال ، مقاله پیش چاپ در سرور آنلاین Arxiv منتشر شده است و هم اکنون تحت بررسی همسالان قرار دارد.
آلن تورینگ کی بود؟ دانشمند پیشگام که به کرک کردن دستگاه Enigma هیتلر کمک کرد تا فقط پس از جنگ جهانی دوم به جرم همجنسگرایی محکوم شود

آلن تورینگ (تصویر) یک ریاضیدان بریتانیایی بود که به خاطر کار خود در ترک کد Enigma در طول جنگ جهانی دوم شناخته شده بود
آلن تورینگ یک ریاضیدان بریتانیایی بود که در 23 ژوئن سال 1912 در مایدا واله ، لندن ، به پدر جولیوس ، کارمند دولت و مادر اتل ، دختر مهندس راه آهن متولد شد.
استعدادهای وی در اوایل مدرسه به رسمیت شناخته شد اما او هنگام شروع سوار شدن در مدرسه شربورن در سن 13 سالگی با معلمان خود مبارزه کرد زیرا او بیش از حد در علم تثبیت شده بود.
تورینگ همچنان در ریاضیات برتری داشت اما زمان حضورش در شربورن نیز در اثر مرگ دوست نزدیک خود کریستوفر مورکوم از سل لرزید. موركوم به عنوان “اولین عشق” تورینگ توصیف شد و او پس از مرگش در کنار مادرش ماند و هر سال در روز تولد موركوم برای او نوشت.
وی سپس به کمبریج رفت و در آنجا در کالج کینگ تحصیل کرد و فارغ التحصیل مدرک درجه یک در ریاضیات بود.
در طول جنگ جهانی دوم ، تورینگ در ترکیدن کدهای مبهم مورد استفاده ارتش آلمان برای رمزگذاری پیام های آنها بسیار مهم بود.
کار او به رهبران متفقین اطلاعات حیاتی در مورد جنبش و اهداف نیروهای هیتلر داد.
مورخان با کوتاه کردن جنگ تا دو سال ، کار تورینگ و همکار خود را در پارک بلچلی در باکینگهامایر اعتبار می دهند و زندگی بی شماری را نجات می دهند و وی در سال 1946 به دلیل خدمات خود به OBE اعطا شد.
تورینگ همچنین به دلیل کار پیشگامانه وی در ریاضیات در دهه 1930 به عنوان پدر علوم کامپیوتر و هوش مصنوعی بسیار دیده می شود.
وی در صورت ارائه الگوریتم قادر به اثبات “دستگاه محاسبات جهانی” بود و می توانست معادلات را انجام دهد – و مقاله ای را در سال 1936 در مجموعه مقالات مجله انجمن ریاضی لندن منتشر کرد که فقط 23 سال داشت.
اما وی در سال 1952 هنگامی که به دلیل فعالیت همجنسگرایان محکوم شد ، که در آن زمان غیرقانونی بود و تا سال 1967 جرم غیرقانونی نبود ، ننگین شد.
برای جلوگیری از زندان ، تورینگ موافقت کرد که “کاستراسیون شیمیایی” باشد – درمان هورمونی که برای کاهش میل جنسی طراحی شده است.
و همچنین آسیب های جسمی و عاطفی ، محکومیت وی منجر به حذف ترخیص امنیتی وی شده بود و به این معنی بود که وی دیگر قادر به کار برای GCHQ ، جانشین کد دولت و مدرسه Cypher ، مستقر در پارک بلچلی نیست.

تورینگ در سال 1946 به دلیل کار با کدگذاری خود در پارک بلچلی ، تصویر ، به OBE اعطا شد ، که به پایان می رسد دو سال زودتر جنگ جهانی دوم
سپس در سال 1954 ، در سن 41 سالگی ، در اثر مسمومیت با سیانید درگذشت. یک استعلام حکم خودکشی را به ثبت رساند ، اگرچه مادرش و دیگران اظهار داشتند که مرگ وی تصادفی است.
هنگامی که بدن او کشف شد ، یک سیب نیمه خورده در کنار تختخوابش قرار گرفت. این هرگز برای سیانید آزمایش نشده است اما حدس می زند که منبع دوز کشنده است.
برخی از نظریه های عجیب تر نشان می دهد که تورینگ با سفید برفی پری و هفت کوتوله وسواس داشت و مرگ وی از سیب مسموم در داستان الهام گرفته شده است.
نخست وزیر آن وقت گوردون براون ، در پی اعتراض عمومی از معالجه و محکومیت وی ، در سال 2009 عذرخواهی عمومی صادر کرد.
وی سپس در سال 2014 عفو سلطنتی پس از مرگ دریافت کرد ، تنها چهارمین چهارم که از پایان جنگ جهانی دوم صادر می شود.
این درخواست توسط وزیر دادگستری کریس گریلینگ ، که تورینگ را یک قهرمان ملی توصیف کرد و به دلیل تمایلات جنسی خود از این قانون ناپدید شد.
دادخواست الکترونیکی که خواستار عفو برای تورینگ بود ، قبلاً 37404 امضا دریافت کرده بود.
قانونی در سال 2017 ، که به طور محاسباتی همه مردان را که به دلیل قانون تاریخی هشدار داده شده یا به دلیل اعمال همجنسگرایان مورد هشدار یا محکوم قرار گرفتند ، به افتخار وی معرفی کرد.