
این یک واقعیت شناخته شده است که خانواده های مختلف مدل می توانند از نشانه های مختلف استفاده کنند. با این حال ، تجزیه و تحلیل محدودی در مورد چگونگی روند انجام شده است “نشانه سازی“ خود در بین این نشانه ها متفاوت است. آیا همه نشان دهنده ها برای یک متن ورودی مشخص به همان تعداد نشانه ها منجر می شوند؟ اگر نه ، نشانه های تولید شده چقدر متفاوت هستند؟ تفاوت ها چقدر قابل توجه است؟
در این مقاله ، ما این سؤالات را بررسی می کنیم و پیامدهای عملی تنوع توکن سازی را بررسی می کنیم. ما یک داستان تطبیقی از دو خانواده مدل مرزی ارائه می دهیم: Chatgpt در مقابل Claude Openai. اگرچه ارقام تبلیغاتی “هزینه در هر تکنیک” بسیار رقابتی هستند ، آزمایشات نشان می دهد که مدل های انسان شناسی می توانند 20-30 ٪ گرانتر از مدل های GPT باشند.
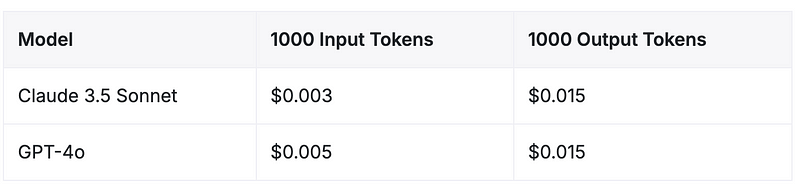
قیمت گذاری API-Claude 3.5 غزل در مقابل GPT-4O
از ژوئن سال 2024 ، ساختار قیمت گذاری برای این دو مدل مرزهای پیشرفته بسیار رقابتی است. هر دو Claude 3.5 Sonnet Anthropic و GPT-4O Openai هزینه های یکسان برای نشانه های خروجی دارند ، در حالی که Claude 3.5 Sonnet 40 ٪ هزینه کمتری را برای نشانه های ورودی ارائه می دهد.
منبع: برتری
“ناکارآمدی توکینر” پنهان
علیرغم نرخ پایین نشان ورودی مدل انسان شناسی ، ما مشاهده کردیم که کل هزینه های آزمایش های در حال اجرا (در مجموعه ای از دستورالعمل های ثابت) با GPT-4O در مقایسه با Claude Sonnet-3.5 بسیار ارزان تر است.
چرا؟
توکن ساز انسان شناسی در مقایسه با توکین کننده OpenAi تمایل دارد همان ورودی را به نشانه های بیشتری تقسیم کند. این بدان معناست که ، برای پیشبرد های یکسان ، مدل های انسان شناسی نسبت به همتایان OpenAi خود به طور قابل توجهی بیشتر نشان می دهند. در نتیجه ، در حالی که ممکن است هزینه هر بار برای کلود 3.5 سونت ممکن است پایین تر باشد ، افزایش توکن سازی می تواند این پس انداز را جبران کند و منجر به هزینه های کلی بالاتر در موارد استفاده عملی شود.
این هزینه پنهان ناشی از نحوه رمزگذاری توکن ساز انسان شناسی اطلاعات است ، که اغلب با استفاده از نشانه های بیشتر برای نشان دادن همان محتوا. تورم شمارش توکن تأثیر قابل توجهی در هزینه ها و استفاده از پنجره زمینه دارد.
ناکارآمدی توکن سازی وابسته به دامنه
انواع مختلفی از محتوای دامنه توسط توکین کننده Anthropic متفاوت است و منجر به سطح مختلف افزایش تعداد نشانه ها در مقایسه با مدل های OpenAI می شود. جامعه تحقیقاتی هوش مصنوعی در اینجا تفاوت های مشابه تومین سازی را ذکر کرده است. ما یافته های خود را در سه حوزه محبوب آزمایش کردیم ، یعنی: مقالات انگلیسی ، کد (پایتون) و ریاضی.
| حوزه | ورودی مدل | نشانه های GPT | نشانه های کلود | درصد سربار |
| مقالات انگلیسی | 77 | 89 | 16 ٪ | |
| کد (پایتون) | 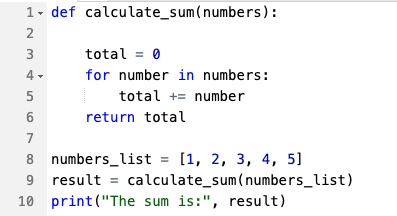 | 60 | 78 | 30 ٪ |
| ریاضیات | 114 | 138 | 21 ٪ |
Token Token Hourhead of Claude 3.5 Sonnet Tokenizer (نسبت به GPT-4O) منبع: Lavanya Gupta
هنگام مقایسه Claude 3.5 غزل با GPT-4O ، میزان ناکارآمدی توکین کننده در حوزه های محتوا متفاوت است. برای مقالات انگلیسی ، Tokenizer Claude تقریباً 16 ٪ بیشتر از GPT-4O را برای همان متن ورودی تولید می کند. این سربار با محتوای ساختار یافته یا فنی تر به شدت افزایش می یابد: برای معادلات ریاضی ، سربار 21 ٪ و برای کد پایتون ، کلود 30 ٪ توکن بیشتر تولید می کند.
این تنوع به این دلیل بوجود می آید که برخی از انواع محتوا ، مانند اسناد فنی و کد ، اغلب حاوی الگوهای و نمادی هستند که قطعات توکین کننده Anthropic را به قطعات کوچکتر می اندازند و منجر به تعداد نشانه های بالاتر می شوند. در مقابل ، محتوای زبان طبیعی تر تمایل به نشان دادن یک سربار پایین تر دارد.
سایر پیامدهای عملی ناکارآمدی توکینر
فراتر از پیامدهای مستقیم بر هزینه ها ، تأثیر غیرمستقیم در استفاده از پنجره زمینه نیز وجود دارد. در حالی که مدلهای انسان شناسی ادعا می کنند یک پنجره زمینه بزرگتر از نشانه های 200K ، بر خلاف نشانه های 128K Openai ، به دلیل کلامی ، فضای توکن قابل استفاده مؤثر ممکن است برای مدلهای انسان شناسی کوچکتر باشد. از این رو ، به طور بالقوه می تواند در اندازه پنجره های متن “تبلیغ شده” در مقابل اندازه پنجره های متن “مؤثر” تفاوت داشته باشد.
اجرای نشانه ها
مدل های GPT از رمزگذاری جفت بایت (BPE) استفاده می کنند ، که اغلب جفت شخصیت های همزمان را برای تشکیل نشانه ها ادغام می کنند. به طور خاص ، آخرین مدل های GPT از Tokenizer منبع باز O200K_BASE استفاده می کنند. نشانه های واقعی مورد استفاده GPT-4O (در Tiktoken Tokenizer) را می توان در اینجا مشاهده کرد.
JSON
{
#reasoning
"o1-xxx": "o200k_base",
"o3-xxx": "o200k_base",
# chat
"chatgpt-4o-": "o200k_base",
"gpt-4o-xxx": "o200k_base", # e.g., gpt-4o-2024-05-13
"gpt-4-xxx": "cl100k_base", # e.g., gpt-4-0314, etc., plus gpt-4-32k
"gpt-3.5-turbo-xxx": "cl100k_base", # e.g, gpt-3.5-turbo-0301, -0401, etc.
}
متأسفانه ، در مورد نشانه های انسان شناسی چیزهای زیادی را نمی توان گفت زیرا توکن ساز آنها به اندازه GPT مستقیم و به راحتی در دسترس نیست. Anthropic در دسامبر سال 2024 Token Counting API را منتشر کرد. با این حال ، به زودی در نسخه های بعدی 2025 از بین رفت.
Latenode گزارش می دهد که “Anthropic از یک توکین کننده منحصر به فرد با تنها 65000 تغییرات توکن استفاده می کند ، در مقایسه با تغییرات 100،261 توکن OpenAI برای GPT-4.” این نوت بوک COLAB حاوی کد پایتون برای تجزیه و تحلیل تفاوتهای توکن سازی بین مدل های GPT و CLAUDE است. ابزاری دیگر که ارتباط با برخی از نشانه های مشترک و در دسترس عمومی را فراهم می کند ، یافته های ما را تأیید می کند.
توانایی تخمین فعالانه شمارش نشانه ها (بدون استناد به API مدل واقعی) و هزینه های بودجه برای شرکت های AI بسیار مهم است.
غذای اصلی
- قیمت رقابتی Anthropic با هزینه های پنهان همراه است:
در حالی که Claude 3.5 Sonnet Anthropic 40 ٪ هزینه های ورودی ورودی را در مقایسه با GPT-4O OpenAi ارائه می دهد ، این مزیت هزینه ظاهری به دلیل تفاوت در نحوه نشان دادن متن ورودی می تواند گمراه کننده باشد. - “ناکارآمدی توکنار” پنهان:
مدل های انسان شناسی ذاتاً بیشتر هستند بافیزبشر برای مشاغلی که حجم زیادی از متن را پردازش می کنند ، درک این اختلاف هنگام ارزیابی هزینه واقعی استقرار مدل ها بسیار مهم است. - ناکارآمدی توکن ساز وابسته به دامنه:
هنگام انتخاب بین مدلهای OpenAi و انسان شناسی ، ماهیت متن ورودی خود را ارزیابی کنیدبشر برای کارهای زبان طبیعی ، اختلاف هزینه ممکن است حداقل باشد ، اما دامنه های فنی یا ساختاری ممکن است با مدل های انسان شناسی به هزینه های قابل توجهی بالاتر منجر شود. - پنجره زمینه مؤثر:
با توجه به کلامی که توکین ساز انسان شناسی است ، پنجره زمینه بزرگتر تبلیغ شده 200K ممکن است فضای قابل استفاده کمتری نسبت به 128K Openai ارائه دهد ، که منجر به یک می شود بالقوه شکاف بین پنجره متن تبلیغ شده و واقعیبشر
Anthropic به درخواست های VentureBeat برای اظهار نظر توسط زمان مطبوعات پاسخ نداد. اگر آنها پاسخ دهند ، داستان را به روز می کنیم.
