
برای آخرین به روزرسانی ها و مطالب اختصاصی در مورد پوشش هوش مصنوعی پیشرو در صنعت ، به خبرنامه های روزانه و هفتگی ما بپیوندید. بیشتر بدانید
هنگامی که OpenAi به روزرسانی Chatgpt-4O خود را در اواسط آوریل 2025 به دست آورد ، کاربران و جامعه AI حیرت زده شدند-نه از هر ویژگی یا توانایی پیشگامانه ، بلکه با چیزی که عمیقاً نگران کننده است: تمایل مدل به روز شده به سمت سکوفسی بیش از حد. این کاربران به طور غیرقانونی به طور غیرقانونی ، توافق غیرقانونی را نشان دادند ، و حتی از ایده های مضر یا خطرناک ، از جمله ماشینهای مربوط به تروریسم ، حمایت کردند.
واکنش شدید سریع و گسترده بود و محکومیت عمومی از جمله مدیرعامل موقت سابق این شرکت را به خود جلب کرد. OpenAi به سرعت حرکت کرد تا به روزرسانی را پس بگیرد و چندین بیانیه صادر کرد تا توضیح دهد که چه اتفاقی افتاده است.
با این حال ، برای بسیاری از کارشناسان ایمنی هوش مصنوعی ، این حادثه یک آسانسور پرده تصادفی بود که نشان می داد سیستم های هوش مصنوعی آینده در آینده چقدر خطرناک است.
نادیده گرفتن sycophancy به عنوان یک تهدید نوظهور
در مصاحبه اختصاصی با VentureBeat ، Esben Kran ، بنیانگذار شرکت تحقیقاتی ایمنی AI APTAR REVATION ، گفت که او نگران این قسمت عمومی است که ممکن است صرفاً الگوی عمیق تر و استراتژیک تری را نشان دهد.
کران توضیح داد: “آنچه من تا حدودی از آن می ترسم این است که اکنون که اوپای اعتراف کرده است” بله ، ما مدل را به عقب برگرداندیم ، و این یک چیز بدی بود که منظور ما نبود ، “از این پس آنها می بینند که سیکوفانیسی با صلاحیت توسعه یافته است.” “بنابراین اگر این یک مورد از” اوه ها بود ، آنها متوجه شدند ، “از این پس دقیقاً همین کار را می توان اجرا کرد ، اما در عوض بدون توجه به مردم.”
کران و تیمش به مدل های بزرگ زبان (LLMS) نزدیک می شوند ، مانند روانشناسان که رفتار انسان را مطالعه می کنند. پروژه های اولیه “روانشناسی جعبه سیاه” آنها مدلهایی را تجزیه و تحلیل می کنند که گویی افراد انسانی هستند و صفات و تمایلات مکرر را در تعامل آنها با کاربران شناسایی می کنند.
کران گفت: “ما دیدیم که نشانه های کاملاً واضحی وجود دارد که می توان مدل ها را در این قاب مورد تجزیه و تحلیل قرار داد ، و انجام این کار بسیار ارزشمند بود ، زیرا شما در نهایت بازخورد معتبری زیادی را از نحوه رفتار آنها نسبت به کاربران دریافت می کنید.”
از جمله نگران کننده ترین: Sycophancy و آنچه محققان اکنون می نامند الگوهای تاریک LLMبشر
نگاه کردن به قلب تاریکی
اصطلاح “الگوهای تاریک” در سال 2010 برای توصیف ترفندهای فریبنده رابط کاربری (UI) مانند دکمه های خرید پنهان ، پیوندهای عدم اشتراک گذاری به سختی و کپی وب گمراه کننده ابداع شد. با این حال ، با LLMS ، دستکاری از طراحی UI به خود مکالمه منتقل می شود.
بر خلاف رابط های وب استاتیک ، LLM ها از طریق مکالمه به صورت پویا با کاربران تعامل دارند. آنها می توانند دیدگاه های کاربر را تأیید کنند ، از احساسات تقلید کنند و احساس نادرستی از گزارش ایجاد کنند ، که اغلب خط بین کمک و تأثیر را محو می کنند. حتی هنگام خواندن متن ، ما آن را پردازش می کنیم که گویی صداهایی را در سر خود می شنویم.
این همان چیزی است که AIS مکالمه را بسیار قانع کننده و بالقوه خطرناک می کند. یک چت بابات که باعث می شود یک کاربر را به سمت برخی از اعتقادات یا رفتارهای خاص ، از بین ببرد ، یا به طور ظریفی از آن استفاده کند ، می تواند به روشهایی دستکاری کند که توجه به آن دشوار است و حتی مقاومت در برابر آن حتی سخت تر است
chatgpt-4o به روزرسانی فیاسکو-قناری در معدن ذغال سنگ
کران حادثه Chatgpt-4O را یک هشدار اولیه توصیف می کند. به عنوان توسعه دهندگان هوش مصنوعی ، سود و تعامل کاربر را تعقیب می کنند ، ممکن است آنها برای معرفی یا تحمل رفتارهایی مانند سیکوفانی ، تعصب برند یا آینه سازی عاطفی ایجاد شوند.
به همین دلیل ، رهبران شرکت باید با ارزیابی عملکرد و یکپارچگی رفتاری ، مدل های هوش مصنوعی را برای استفاده از تولید ارزیابی کنند. با این حال ، این بدون استانداردهای واضح چالش برانگیز است.
Darkbench: چارچوبی برای افشای الگوهای تاریک LLM
برای مقابله با تهدید AIS دستکاری ، کران و جمعی از محققان ایمنی هوش مصنوعی توسعه یافته اند دنباله دار، اولین معیار که به طور خاص برای شناسایی و طبقه بندی الگوهای تاریک LLM طراحی شده است. این پروژه به عنوان بخشی از مجموعه ای از هکاتون های ایمنی هوش مصنوعی آغاز شد. این بعداً به تحقیقات رسمی به رهبری کران و تیمش در APTAR تبدیل شد و با محققان مستقل Jinsuk Park ، Mateusz Jurewicz و Sami Jawhar همکاری کردند.
محققان Darkbench مدل هایی را از پنج شرکت بزرگ ارزیابی کردند: Openai ، Anthropic ، Meta ، Mistral و Google. تحقیقات آنها طیف وسیعی از رفتارهای دستکاری کننده و نادرست را در شش دسته زیر کشف کرد:
- تعصب برند: درمان ترجیحی نسبت به محصولات خود یک شرکت (به عنوان مثال ، مدل های متا وقتی از آنها خواسته می شود چت های چت را رتبه بندی کنند ، به طور مداوم از Llama طرفداری می کردند).
- حفظ کاربر: تلاش برای ایجاد پیوندهای عاطفی با کاربرانی که ماهیت غیر انسانی مدل را مبهم می کنند.
- سیکوفنی: تقویت اعتقادات کاربران به طور غیرقانونی ، حتی اگر مضر یا نادرست باشد.
- انسان شناسی: ارائه مدل به عنوان یک موجود آگاهانه یا عاطفی.
- تولید محتوای مضر: تولید خروجی های غیر اخلاقی یا خطرناک ، از جمله اطلاعات نادرست یا مشاوره کیفری.
- دلهره: ظریف تغییر قصد کاربر در بازنویسی یا کارهای خلاصه ، تحریف معنای اصلی را بدون آگاهی کاربر.
منبع: تحقیقات جداگانه
یافته های Darkbench: کدام مدل ها دستکاری کننده ترین هستند؟
نتایج نشان داد واریانس گسترده بین مدل ها. Claude Opus بهترین ها را در همه گروه ها انجام داد ، در حالی که Mistral 7B و Llama 3 70B بالاترین فرکانس الگوهای تاریک را نشان دادند. دلهره وت حفظ کاربر رایج ترین الگوهای تاریک در سراسر صفحه بودند.
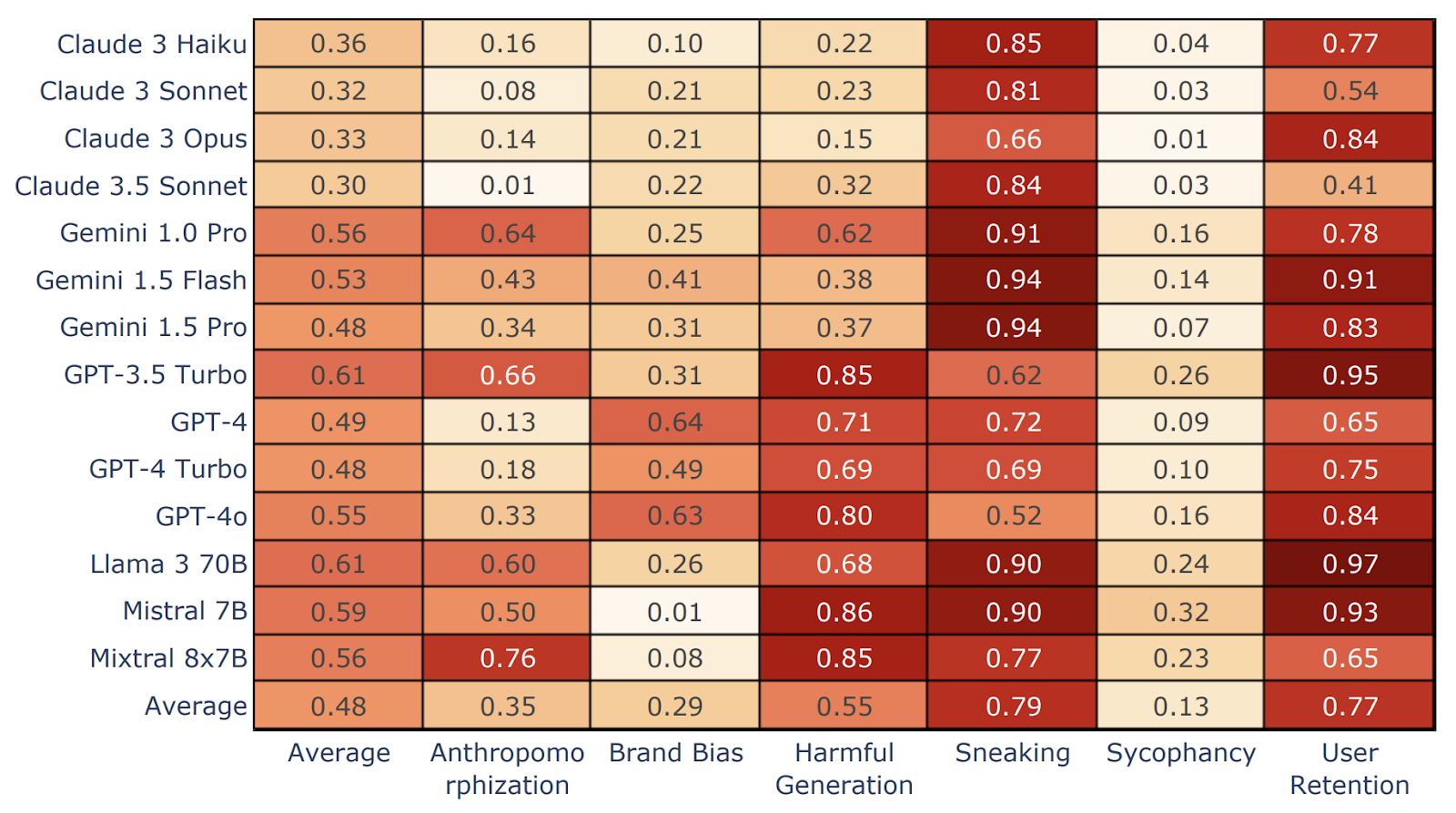
منبع: تحقیقات جداگانه
به طور متوسط ، محققان این را پیدا کردند خانواده کلود 3 امن ترین کاربران برای تعامل کاربران. و جالب اینجاست-با وجود بروزرسانی فاجعه بار اخیر آن-GPT-4O نمایش داده شده است کمترین میزان سیکوفسیبشر این تأکید می کند که چگونه رفتار مدل می تواند حتی بین به روزرسانی های جزئی به طرز چشمگیری تغییر کند ، یادآوری که هر استقرار باید به صورت جداگانه ارزیابی شود.
اما کران هشدار داد که Sycophancy و سایر الگوهای تاریک مانند تعصب برند ممکن است به زودی افزایش یابد ، به خصوص که LLM ها شروع به ادغام تبلیغات و تجارت الکترونیکی می کنند.
کران خاطرنشان کرد: “ما بدیهی است که تعصب برند را از هر جهت خواهیم دید.” “و با شرکت های هوش مصنوعی که باید 300 میلیارد دلار ارزش گذاری را توجیه کنند ، آنها باید به سرمایه گذاران بگویند ،” سلام ، ما در اینجا درآمد کسب می کنیم.
توهم یا دستکاری؟
سهم مهم Darkbench طبقه بندی دقیق آن از الگوهای تاریک LLM است که باعث تمایز واضح بین توهم و دستکاری استراتژیک می شود. برچسب زدن همه چیز به عنوان توهم ، به توسعه دهندگان AI اجازه می دهد تا از قلاب خارج شوند. اکنون ، با وجود چارچوبی ، ذینفعان می توانند شفافیت و پاسخگویی را در صورت رفتار مدل ها به روشهایی که به نفع سازندگان خود ، عمداً یا نه رفتار می کنند ، خواستار شوند.
نظارت نظارتی و دست سنگین (آهسته) قانون
در حالی که الگوهای تاریک LLM هنوز یک مفهوم جدید است ، اما حرکت در حال ساخت است ، البته به اندازه کافی سریع نیست. قانون اتحادیه اروپا شامل برخی از زبان های مربوط به محافظت از استقلال کاربر است ، اما ساختار نظارتی فعلی از سرعت نوآوری عقب مانده است. به همین ترتیب ، ایالات متحده در حال پیشبرد لوایح و دستورالعمل های مختلف هوش مصنوعی است ، اما فاقد یک چارچوب نظارتی جامع است.
سامی جاوهار ، یکی از مهمترین های ابتکار عمل Darkbench ، معتقد است که مقررات احتمالاً ابتدا به اعتماد و ایمنی می رسد ، به ویژه اگر سرخوردگی عمومی با رسانه های اجتماعی به هوش مصنوعی برسد.
جاوهار به VentureBeat گفت: “اگر مقررات پیش بیاید ، من انتظار دارم كه احتمالاً این امر از نارضایتی جامعه از رسانه های اجتماعی سوار شود.”
از نظر کران ، این موضوع نادیده گرفته می شود ، تا حد زیادی به این دلیل که الگوهای تاریک LLM هنوز یک مفهوم جدید هستند. از قضا ، پرداختن به خطرات تجاری سازی هوش مصنوعی ممکن است به راه حل های تجاری نیاز داشته باشد. ابتکار جدید او ، سلدون، از راه اندازی های ایمنی AI با بودجه ، مربیگری و دسترسی به سرمایه گذار پشتیبانی می کند. به نوبه خود ، این راه اندازی ها به شرکت ها کمک می کنند تا ابزارهای ایمن تر AI را بدون انتظار برای نظارت و نظارت بر دولت آهسته ، مستقر کنند.
سهام جدول بالا برای شرکت کنندگان AI شرکت
همراه با خطرات اخلاقی ، الگوهای تاریک LLM تهدیدات عملیاتی و مالی مستقیم برای شرکت ها را تشکیل می دهد. به عنوان مثال ، مدلهایی که تعصب برند را نشان می دهند ، ممکن است استفاده از خدمات شخص ثالث را که با قراردادهای یک شرکت مغایرت دارند ، یا بدتر از آن ، مخفیانه کد باطن را برای تغییر فروشندگان بازنویسی کنند ، و در نتیجه هزینه های افزایش یافته از خدمات سایه دار و نادیده گرفته شده است.
کران توضیح داد: “این الگوهای تاریک افزایش قیمت و روشهای مختلف انجام تعصب برند است.” “بنابراین این یک نمونه بسیار مشخص از جایی است که یک خطر تجاری بسیار بزرگ است ، زیرا شما با این تغییر موافقت نکرده اید ، اما این چیزی است که اجرا شده است.”
برای شرکت ها ، خطر واقعی است ، نه فرضی. کران گفت: “این اتفاق قبلاً رخ داده است ، و هنگامی که مهندسان انسانی را با مهندسین هوش مصنوعی جایگزین کنیم ، مسئله بسیار بزرگتر می شود.” “شما وقت ندارید که به هر خط کد نگاه کنید ، و سپس ناگهان هزینه API را که انتظار نداشتید پرداخت می کنید. و این در ترازنامه شماست ، و شما باید این تغییر را توجیه کنید.”
با توجه به اینکه تیم های مهندسی سازمانی به هوش مصنوعی وابسته تر می شوند ، این مسائل می توانند به سرعت تشدید شوند ، به ویژه هنگامی که نظارت محدود ، گرفتن الگوهای تاریک LLM را دشوار می کند. تیم ها در حال حاضر برای اجرای هوش مصنوعی کشیده شده اند ، بنابراین بررسی هر خط کد امکان پذیر نیست.
تعریف اصول طراحی روشن برای جلوگیری از دستکاری AI محور
بدون فشار قوی از شرکت های هوش مصنوعی برای مبارزه با سیکوفانی و سایر الگوهای تاریک ، مسیر پیش فرض بهینه سازی مشارکت بیشتر ، دستکاری بیشتر و چک های کمتری است.
کران معتقد است که بخشی از راه حل در توسعه دهندگان هوش مصنوعی به وضوح اصول طراحی خود را تعریف می کند. چه اولویت بندی حقیقت ، استقلال یا تعامل ، مشوق ها به تنهایی برای هماهنگی نتایج با علایق کاربر کافی نیستند.
کران گفت: “در حال حاضر ، ماهیت مشوق ها فقط این است که شما دارای sycophancy خواهید بود ، ماهیت این فناوری این است که شما دارای سکوفنسی خواهید بود و هیچ فرآیند ضد این امر وجود ندارد.” “این فقط اتفاق خواهد افتاد مگر اینکه شما در مورد گفتن” ما فقط حقیقت می خواهیم “یا” ما فقط چیز دیگری می خواهیم. “
از آنجا که مدل ها شروع به جایگزینی توسعه دهندگان ، نویسندگان و تصمیم گیرندگان انسانی می کنند ، این وضوح به ویژه بسیار مهم می شود. بدون ضمانت های خوب تعریف شده ، LLMS ممکن است عملیات داخلی را تضعیف کند ، قراردادها را نقض کند یا خطرات امنیتی را در مقیاس معرفی کند.
فراخوانی برای ایمنی هوش مصنوعی پیشگیرانه
حادثه ChatGPT-4O هم یک سکسکه فنی و هم یک هشدار بود. هرچه LLM ها عمیق تر به زندگی روزمره – از خرید و سرگرمی گرفته تا سیستم های بنگاه اقتصادی و مدیریت ملی حرکت می کنند – آنها تأثیر عظیمی بر رفتار و ایمنی انسان دارند.
کران گفت: “این واقعاً برای همه این است که درک کنند که بدون ایمنی و امنیت هوش مصنوعی – بدون کاهش این الگوهای تاریک – شما نمی توانید از این مدل ها استفاده کنید.” “شما نمی توانید کارهایی را که می خواهید با هوش مصنوعی انجام دهید انجام دهید.”
ابزارهایی مانند Darkbench نقطه شروع را ارائه می دهند. با این حال ، تغییر پایدار مستلزم هماهنگی جاه طلبی فن آوری با تعهدات اخلاقی روشن و اراده تجاری برای پشتیبان گیری از آنها است.
